




INTRODUCTION
By now most of the world has been astonished with ChatGPT from OpenAI and its various abilities so much so that the debate of Artificial General Intelligence AGI has been restarted and given a fresh lease. Such is the impact of ChatGPT (and other similar models, stable diffusion for image generation) that various governments are already looking into incorporating AI at the same time they are also concerned about its potential or being misused and hence any regulations regarding its use are being discussed and proposed. In fact, a group of AI researchers have called for a moratorium on releasing new models (citation). Many jobs are being replaced by such models while other are transformed. In this article, we would try to understand what this amazing technology is and how various industries can use it for their own benefit. We shall start by unwrapping the term LLMs and discuss language models and some of the earlier attempts and their shortcomings. We will then discuss what powers the current LLM and how to train them. We will then discuss how to make an LLM follow human instructions and finally end with some of the use-cases where these LLMs can be used.
UNWRAPING THE TERM LLM
So, what does large and language model in the term Large Language Models mean? I think large is clear in its meaning, however the latter needs some introduction. Language Model is a term used by researchers to define a probabilistic model which finds the probability of a given sequence of terms. For example, what is the probability of the sentence The quick brown fox jumps over a lazy dog. In pure mathematical terms, given a sequence of words 𝑊 = (𝑤1, 𝑤2, … , 𝑤𝑘), a language model finds the probability:

Before we discuss how to estimate this probability, we would like to understand why we might need to know this probability and what consequence does it have? Let’s first analyze how we humans learn and use the language. Most of us use intuition to make sentences and judge the grammatical correctness or appropriateness of a text, without necessarily being taught the rules or us remembering the grammatical rules precisely. Our brains have this amazing capability to deduce this intuition from regular use of language. Language models can be understood to be modelling this intuition from exactly the same source humans deduce it, i.e., language (in the form of text). Probabilistic likelihood is the tool that the language models use to measure it. Calculating the probability therefore gives us a measure of finding the most likely sequence versus an absurd or unlikely sequence. For example, consider the sentence, I am looking … my purse. The sequence with a preposition (at, for, towards, in, into etc.) would be most probable rather than having any other word in its place (It wouldn’t make sense to have computer/ cat/ hand etc. in the blank space). Therefore, the word sequences that are more likely will have a higher probability in contrast to those that are grammatically wrong or semantically incorrect. In fact, the next word prediction or masked word prediction is the pseudo-task used to train today’s LLMs, more on that later. Another benefit of language modelling is in machine translations since the correct translation will be more likely and hence with more probability. We can argue on similar lines on the tasks of information retrieval, speech recognition, summarization etc.
HOW TO CALCULATE/ ESTIMATE THE PROBABILITY?
From the product rule of probability, we know that,
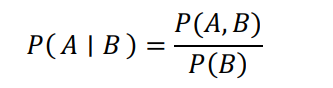
Therefore, equation (1) above can be expanded as below:
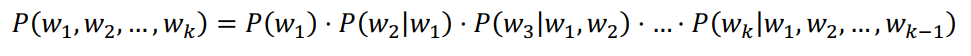
That is, the probability of the whole word sequence is the product of the probability of each word given all the previous words in the sequence. For example, the probability, 𝑃 of the sentence “The quick brown fox jumps over the lazy dog” would be:

However, calculating the exact probability this way is intractable for longer sequences because the number of terms grows exponentially. Language models therefore make simplifying assumptions, like only considering a limited context of a few words before and after the target word when calculating these conditional probabilities. They also use probability distributions over words and their contexts rather than exact values.
We, therefore, have 𝑛-Grams where 𝑛 defines the number of words in the joint probability, sometimes also called the context window. Setting 𝑛 = 3, would be a trigram and equation (2) would be:
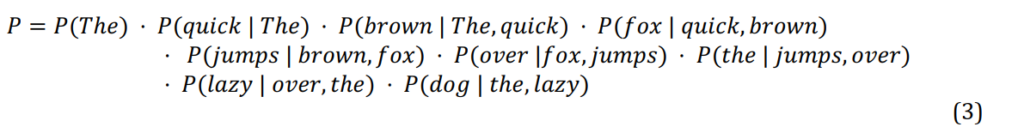
We can already see the limitation of a smaller 𝑛, because it provides a too little context for the next word prediction.
There have been other methods of language modelling like the Hidden Markov Model (HMM), Statistical Modelling etc., however all of them suffer from the limitation of context window. Also designing and creating the dataset is sometimes prohibitive since we need to deal with probabilities explicitly.
TRANSFORMERS TO THE RESCUE
Transformers are a type of neural network that are sequence-to-sequence, that is, they take as input a sequence of tokens and output another sequence of tokens. (Tokens can be understood as roughly being words but not necessarily words every time the way we understand them.)
Transformer is the engine behind the extraordinary power and success of today’s LLMs, and attention is the key architectural thing in these transformers. We won’t explain what transformers are and their inner architecture here, however one can refer to the excellent blog by Jay Alammar and another one by Peter Bloem. To fully grasp the importance and formidable capabilities of transformers without delving into their intricate workings, it is crucial to retrace the origins of deep learning, which initially gained prominence in computer vision. In the pre-deep learning era, machine learning comprised two primary stages: feature engineering and model training. Domain-specific features were meticulously crafted for individual datasets and tasks, making them incompatible with different tasks. However, this paradigm shifted with the emergence of Convolutional Neural Networks (CNNs) trained on large-scale datasets like ImageNet for image classification. CNNs not only outperformed their predecessors but also introduced a new training paradigm known as transfer learning.
Transfer learning involves leveraging a pre-trained model, typically excluding the final layers (since neural networks are comprised of stacked layers of neurons), which was trained on a distinct task using different data and applying it to a target task. For example, ResNet, a widely used CNN model, is trained on the ImageNet dataset. Suppose we encounter a new dataset comprising only a few hundred or thousand samples. Training a specialized model using this small dataset would be inefficient due to its limited size. Instead, we utilize ResNet as a feature extractor and append additional classification layers. Subsequently, we train this modified architecture on the new dataset, yielding improved results. The underlying rationale for this improvement lies in the fact that ResNet has already learned general features from a large dataset, which are applicable to a wide range of images.
However, prior to the emergence of transformers, transfer learning was not feasible for language data, particularly textual data. Transformers not only enable transfer learning but also learn vector representations, known as embeddings, that capture the semantic properties of text. These embeddings empower transformers to comprehend and analyse the underlying meaning conveyed within textual data. What CNNs are for images transformers are for the text.
CONNECTING THE DOTS TOGETHER
Transformers are fine but how does it fit as a language model; you might ask? There are two types of learning algorithms – supervised and unsupervised. In supervised learning, the data we use for training has two components – the data itself and a label and our objective is to train a model such that given some data it should output a label that is as close to the actual label as possible. However as one can guess, having such kind of data is very expensive because most of the times it requires domain specialists to create and label it, for example, radiologists. Unlabelled data is available in abundance, though. Unsupervised learning utilises this unlabelled data.
Now for language we have tons and tons of data on the internet. We therefore create a pseudotask – text completion/ prediction and train a model to do that. In essence, we use large amount of data and train a language model using transformers. Why transformers, you might ask? That is because of their remarkable ability to model and process very long sequences.
So, in a nutshell the reason today’s LLMs are so capable is that they are language models trained on very large datasets, and they can process very long sequences of text, thereby using the data more effectively than other previous methods.
However, pre-training on very large datasets is not the only secret in the sauce. Today’s LLMs are very good at instruction following, and to achieve that we need two more ingredients.
MAKING LLMS FOLLOW INSTRCUTIONS
There are two methods that researchers use to enable an LLM follow instructions – Supervised Fine Tuning (SFT) And Reinforcement Learning by Human Feedback (RLHF).Supervised Fine Tuning (SFT) is a method where an LLM is initially pre-trained on a large dataset and then fine-tuned using labelled data. This process enhances the model’s ability to understand and generate text according to specific instructions. This is a very important and powerful method. Some research suggests even a thousand well-crafted examples are enough to fine-tune a pretrained foundational model towards following instructions. (It must be noted that fine-tuning is not restricted to the above-mentioned task rather it is a much wider term for any type of model.)Reinforcement Learning by Human Feedback (RLHF) is another approach used to train LLMs. In RLHF, the agent learns from human feedback in the form of preferences or ratings. The agent then uses this feedback to optimize its policy using reinforcement learning (RL) through an optimization algorithm like Proximal Policy Optimization (PPO).In some cases, both SFT and RLHF methods are used sequentially, while in others, RLHF may be entirely eliminated from the training process. The choice of method depends on the specific requirements and goals of the language model being developed.
CONCLUSION
Large Language Models have emerged as powerful tools that have captivated the world. The development and utilization of LLMs like ChatGPT showcase the remarkable progress made in natural language processing. Throughout this article, we have delved into the world of LLMs, understanding their capabilities. We started by unwrapping the term LLM and providing insights into language models and their earlier iterations, highlighting their limitations. As we progressed, we delved into the mechanisms powering current LLMs and the process of training them.One key aspect we examined was how to make LLMs follow human instructions. We discussed two prominent approaches: Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). These techniques enable LLMs to understand and respond to human instructions, making them more intuitive and user-friendly.In the next article we shall discuss some use-cases where LLMs can be helpful along with some of the limitations and risks they pose.

